So, what does this mean to other startup's with a equal or even more ambitious goal to achieve? Why startup's need care about big data? How to collect and make sense of it? How to build the infrastructure to deal with big data? How can all the big data stuff to be pragmatic rather than fancy showcase? This blog is about to address all above questions in a very practical way.
To start with, a typical pattern of Internet upstart is usually built based on some sort of cloud hosting environment. Among all major cloud vendors (Amazon AWS, Rackspace, Google App Engine , Microsoft Azure etc.), AWS seems to be the most natural choice for startup's because of its deep tech stack and battle hardened infrastructure(major outage did happen sometimes :) ).
Now, back to the topic, if you run everything on AWS cloud and want your big data gig, how you would actually build it? Let's answer the question by first splitting the design requirements into 2 major categories:
- Big Data : Able to store and access large scale data set and support deep mining
- Fast Data : Support production dashboard and near real-time BI need
Some companies might focus one more than the other, but eventually both will become critical as your business advances. Here at Tapjoy, we are experiencing high data demands from both categories. We are seeing more than 200 Million mobile user sessions on daily basis. Both our internal business folks and external partners want to access granular stats in near-realtime fashion. Meanwhile, our engineering and science group need build models to facilitate various data driven applications such as ad ranking optimization, app recommendation, behavior targeting etc. So we come up with the architecture below and built it on Amazon AWS:
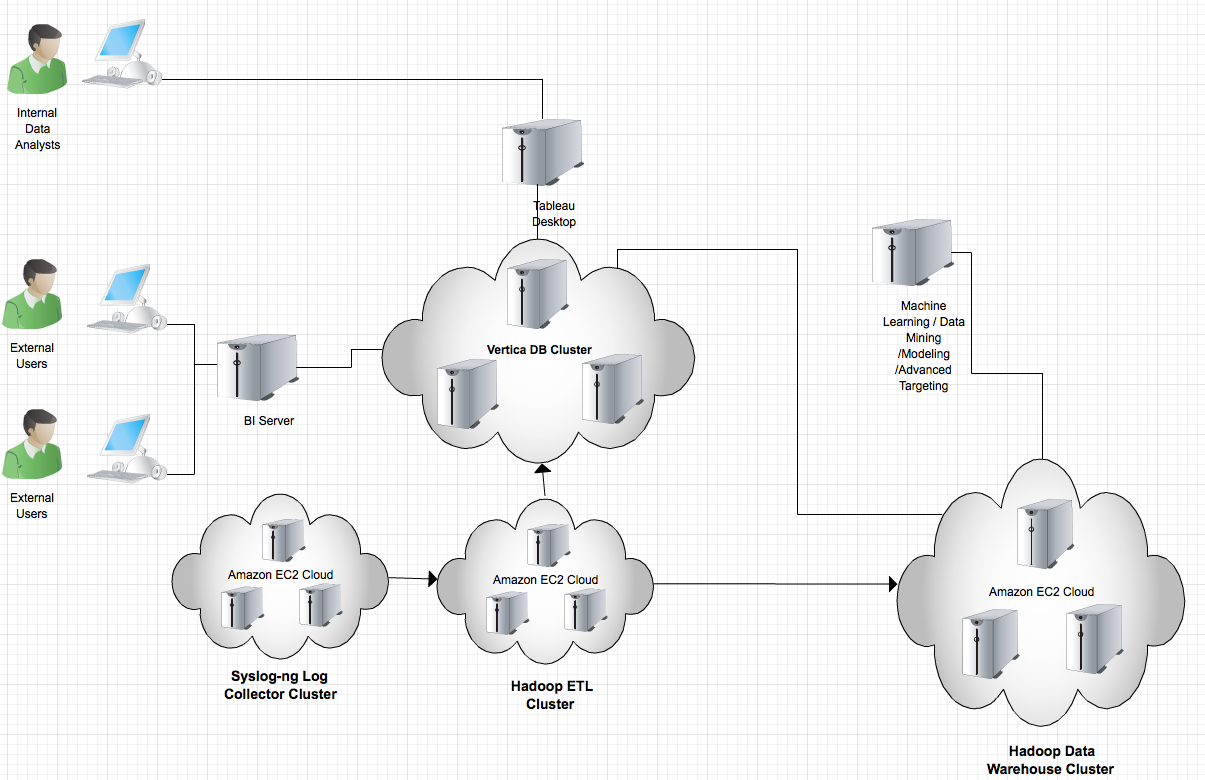
- Syslog-ng log Collector Cluster : responsible of collecting logs from production web server, produce batch logs every minute
- Hadoop ETL Cluster : pick up the logs collected by Syslog-ng and run E(extraction) and T(transformation) of the raw logs
- Hadoop Data Warehouse : pulls post ETL data from ETL cluster and load them into Hadoop HDFS. Ready to be used by various data mining/modeling processes (e.g. Mahout ML algorithms)
- Vertica DB Cluster : column oriented fast analytical DB for near real-time reporting and dashboarding. It also pulls data from the Hadoop ETL cluster
- BI Suite : Tableau Desktop is neat solution for internal analysts for daily drag & drop type of pivotal analysis
Everything in this system runs on AWS cloud, it uses both EBS and S3 for data redundancy and backup. There are some nice features about this system:
- SCALABLE : can handle 1 billion raw events/day with modest number of EC2 nodes. Beyond that, the system scales linearly,simply by adding more nodes.
- ROBUST : the infrastructure is designed assuming any node can be down at any moment. Every component in the system has its back up plan.
- FAULT-TOLERENT : System components are properly separated to avoid errors from cascading down flow, which helps isolate problems and solve them. Data at difference stages all get back up actively, which can contribute to quick recovery from system failure.
The overall end-to-end delay from production to dashboard is within 30 minutes and users are allowed to perform any deep and interactive queries that operates at the most granular level - raw events.
To build and run such a big data infrastructure purely on AWS presents a lot of challenges, in the posts that follow, I will talk about many tricks we learn along the way to get our big data up running healthily on the Cloud.
No comments:
Post a Comment