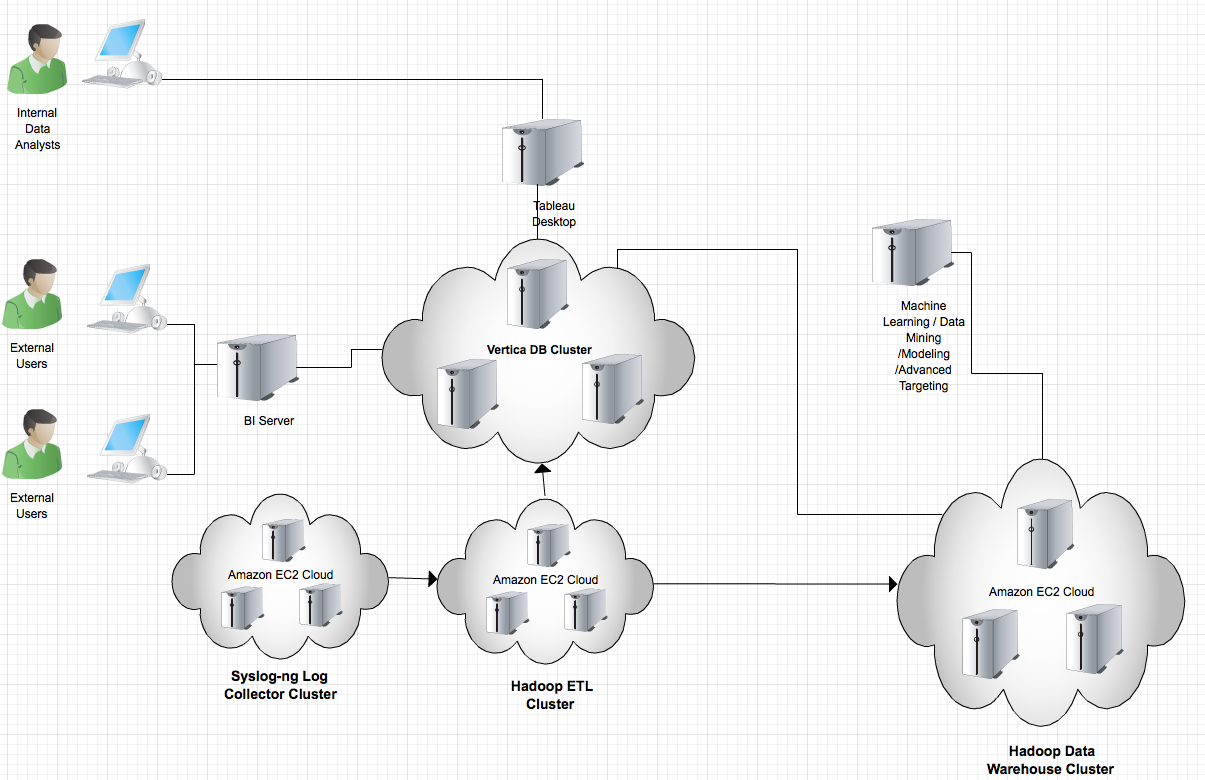
In our case, we once ran a 9-node Hadoop cluster on EC2. Over 3-month period, we lost 4 of the nodes which no longer show up in the Hadoop jobtracker dashboard. When we are fixing the node, we found that usually it's not any Hadoop related failure that caused the trouble, rather it's EC2 related, mostly storage/network. To fix the problem, it usually requires rebooting the problematic node. But then it introduces another problem- data loss.
Here are the best practice and steps we figured to contain the data loss problems and it works quite well.
Frist of all, you need set the replication factor of HDFS to be 3. Before launching the Hadoop cluster, go to your namenode' hdfs-site.xml under conf sub directory of HDFS and set "dfs.replication" to be 3. It should look like following :
<property>
<name >
dfs.replication
</name >
< value>3 </value>
</property>
As you do this, you are assured each block of data on HDFS will be replicated to 3 nodes. You will be fine even if you lose 2 data nodes in your cluster - but you still need take immediate action no matter what if 1 data node disappears.
In case one, when you see data node loss, first login to the failed EC2 instance to see what's wrong there. If you can recover it by restarting datanode and tasktracker without rebooting the instance, congratulations! Here are steps you can take(assume you are running CDH3):
> service hadoop-0.20 datanode stop
>service hadoop-0.20 tasktracker stop
>service hadoop-0.20 datanode start
>service hadoop-0.20 tasktracker start
Try to connect to your jobtracker dashboard now, if you see the correct number of nodes, you are done.
In case 2, you are not that lucky, but no worry. Reboot the instance. Check with your instance-store storage space by :
> df -h
If you are using m2.4xlarge EC2 instances(highly recommend this type of instance for building Hadoop cluster), you will notice that you lose all your ephemeral storage on the instance. In our case, that's where HDFS is located(I will explain in following posts why we go with ephemeral storage). So as the first step, we need remount this storage device :
>umount /mnt
>yes Y|mdadm --create --verbose /dev/md0 --level=0 -c256 --raid-devices=2 /dev/sdb /dev/sdc
>yes Y|blockdev --setra 65536 /dev/md0
>yes Y|mkfs.xfs -f /dev/md0
>mount /dev/md0 /mnt
Here we make a RAID0 based on 2 ephemeral devices coming with m2.4xlarge instance and make an xfs file system on it then mount the device to /mnt, now you will see total 1.7 TB space on /mnt if you run df -h
The following steps depend on how you actually configure your Hadoop/HDFS, but if you are using CDH3, below are recommended steps:
>mkdir -p /mnt/hadoop/dfs/name
>mkdir -p /mnt/hadoop/dfs/data
>mkdir -p /mnt/hadoop/dfs/namesecondary
>chown -R hdfs:hadoop /mnt/hadoop/dfs/name /mnt/hadoop/dfs/data /mnt/hadoop/dfs/namesecondary
>chmod -R a+rw /mnt/hadoop/dfs/name /mnt/hadoop/dfs/data /mnt/hadoop/dfs/namesecondary
>mkdir -p /mnt/tempDirForHadoop
>chmod a+w /mnt/tempDirForHadoop
>mkdir -p /mnt/tempDirForHadoop/dfs/tmp
>chmod -R a+rw /mnt/tempDirForHadoop/dfs/tmp
>mkdir -p /mnt/tempDirForHadoop/s3
>chmod -R a+rw /mnt/tempDirForHadoop/s3
>mkdir -p /mnt/tempDirForHadoop/mapred/local
>chown -R mapred:hadoop /mnt/tempDirForHadoop/mapred/local
>chmod -R a+rw /mnt/tempDirForHadoop/mapred/local
>mkdir -p /mnt/tempDirForHadoop/mapred/temp
>chmod -R a+rw /mnt/tempDirForHadoop/mapred/temp
After this, run:
>service hadoop-0.20 datanode start
>service hadoop-0.20 tasktracker start
Check back to your jobtracker dashboard, you will see the recovered node appearing up there. However, we are not done yet. Even if there is no data loss for the Hadoop cluster, the newly recovered node has no data on it. Also, Hadoop cluster won't automatically re-balance among the data nodes unless you instruct it to. Now login to your namenode, go to Hadoop home directory and run:
>bin/start-balancer.sh -threshold 5
5 is a good number to use, the lower the number, the more evenly data is distributed across nodes. The tradeoff here is this takes network bandwidth to move around data among data nodes. It runs in background, but could affect regular MapReduce job running on the cluster. The re-balance job takes a while depending on how big the underlying data is. If you login to the recovered data node after a while. You will see data size grows significantly under /mnt.
In case 3, you are even unluckier - the instance is completely gone or non-functional. Again, not end of the world, just a few more miles to travel.
- Terminate the bad instance, boot a new one with pre-built AMI used for your Hadoop cluster.
- Go to every node of the cluster, change the "slaves" file under your Hadoop conf directory, remove the bad instance IP or DNS name from the list and add in the new replacement node.
- Follow all steps under case without starting the datanode and tasktracker service on the replacement node.
- Login to the namenode, run following commands:
> service hadoop-0.20 namenode stop
> service hadoop-0.20 jobtracker stop
>service hadoop-0.20 namenode start
>service hadoop-0.20 jobtracker start - Login to the replacement datanode, run:>service hadoop-0.20 datanode start>service hadoop-0.20 tasktracker start
- Login back to namenode and go to Hadoop home directory, run:>bin/start-balancer.sh -threshold 5
Go back to jobtracker dashboard now, you should see a healthy cluster running now.
Except for case 3, for which you have to restart your namenode, you can swap the bad node and recover it w/o interrupting the cluster from running its M/R jobs, that's why we call it "hot swap".